TagChunker :
mécanisme de construction et
évaluation
Gil
Francopoulo
Résumé : Après un descriptif de lalgorithme
danalyse, larticle décrit comment est développée et maintenue la grammaire du
système. Puis, il sera montré que loin dêtre un processus ajouté a posteriori,
lévaluation est une tâche récurrente sinon quotidienne qui oriente de manière
précise le planning dévolution du chunker et de la grammaire
associée.
1 Introduction
Elaborer un
système danalyse syntaxique qui construise une structure complète est une tâche
ardue si nous visons à la fois une large couverture et une bonne qualité. Mais
pour un certain nombre dapplications, comme lextraction de termes ou
lindexation de textes, lanalyse complète nest pas nécessaire : une
analyse partielle suffit, du moment que les ambiguïtés lexicales sont résolues
et que les groupes nominaux et prépositionnels élémentaires (non-récursif) sont
formés.
Lanalyseur que nous présentons réalise deux
tâches : létiquetage morpho-syntaxique (i.e. « Part of speech
tagging ») et lanalyse syntaxique en syntagmes élémentaires
(i.e. « chunking »). Notons que nous ne traitons pas les
opérations de délimitation de propositions (i.e. « clause
bracketing »).
La notion de « chunk », dans le
cadre dun analyse partielle a été introduite dans les années 90 par Abney
[Abney 91] : « the typical chunk consists of a simple content word
surrounded by a constellation of function words, matching a fixed
template ». Elle a été reprise et complétée dans [Abney 96].
Pour une présentation simple et efficace de
toutes ces notions, vous pouvez consulter [Vergne 00]. Si vous
cherchez un état de lart à jour avec des comparaisons entre analyseurs,
veuillez consulter [Monceaux 02] et [Gala 01]. Pour un panorama un peu plus
large, voir [Abeillé 00].
2 La chaîne
danalyse
La totalité des outils de traitement de la
langue de Tagmatica est organisée en une boîte à outils nommée TagTools (cf. http://www.tagmatica.com/).
Lentrée de la chaîne danalyse est un
document rédigé en français ou en anglais.
Le document va traverser les modules de
traitement suivants :
Etape-1 : Le détecteur de format est
appliqué afin de déterminer quel est le format parmi 17 valeurs possibles. Ce
sera par exemple : HTML, RTF ou bien XML.
Etape-2 : En fonction du format, un
segmenteur (i.e. tokenizer) en phrases et en mots est appelé (6 segmenteurs
existants). On notera que les marques typodispositionnelles, quand elles sont
présentes, sont exploitées au même titre que la ponctuation. Ainsi, pour un
format richement balisé comme HTML, les balises de marque de début de liste sont
exploitées. A contrario, quand le format est moins riche, comme le format texte,
le segmenteur dispose dun nombre limité dindices et nexploite que la
ponctuation. Notons que les marques typodispositionnelles ne sont pas transmises
aux traitements ultérieurs.
Etape-3 : Un détecteur de langue est
appliqué (10 langues reconnues).
Etape-4 : En fonction de la langue, un
analyseur morphologique français ou bien anglais est appelé. En sortie, chaque
mot est considéré comme mot simple ou bien composé. Chaque mot produit une ou
plusieurs analyses. Chaque analyse comporte la forme lemmatisée et létiquette
morpho-syntaxico-sémantique. Il y a 188 étiquettes différentes.
Etape-5 : Si un mot est inconnu, un
rattrapeur de fautes nommé TagCorrector est appliqué. A la sortie, tous les mots
possèdent au moins une analyse lexicale : il y a toujours un résultat.
Quand il y a plusieurs résultats, nous avons affaire à une ambiguïté
lexicale.
Etape-6 : TagChunker est appliqué sur
chaque phrase.
3 Entrées-sorties de
TagChunker
Nous venons de voir que lentrée du chunker
est une phrase.
Les appels sont indépendants les uns des autres. Ce nest pas un système à
mémoire.
La sortie du chunker est une suite plate de
syntagmes élémentaires. Les syntagmes ne sont pas rattachés entre eux. On ne
distingue pas les actants des circonstants. Ils sont appelés
chunks.
Pour une phrase donnée, la sortie est
constituée :
a) de la
liste des chunks,
b) du type de
phrase : interrogative, déclarative etc.
Chaque chunk est
composé :
a) de la
liste des mots lexicalement désambiguïsés du chunk. Le système détermine donc
les frontières de groupes.
b) du nom du
chunk. Cest une valeur à prendre parmi 21 étiquettes. Ce sera par exemple,
GV, GN, GP ou
GpotentiellementNominalOuPrépositionnel.
4 Algorithme
danalyse
Un automate de reconnaissance est appliqué
sur la phrase :
Si un seul résultat est
produit
Alors, il est considéré comme étant le bon
résultat
Si plus dun résultat est
trouvé
Alors, un algorithme délagage est appliqué
pour ne retenir quun seul résultat
Si il ny a aucun résultat
Alors, des micro-grammaires sont combinées
afin de produire des analyses candidates
Si un seul résultat est produit
Alors, il est considéré comme étant le bon résultat
Si plus dun résultat est produit
Alors, lélagage est appelé afin de ne retenir quun seul
résultat
Sinon, cest un échec.
Un mot de la combinaison des
micro-grammaires : nous faisons lhypothèse quil existe une suite (idéale)
de micro-grammaires capable danalyser entièrement la phrase. Comme nous ne
connaissons pas précisément cette suite idéale, nous procédons à toutes les
permutations et nous élaguons.
Lalgorithme
actuel délagage est une cascade de filtres statistiques qui combinent les
informations suivantes :
a) les
ambiguïtés entre étiquettes : étant donnée une combinaison détiquettes,
quelle est létiquette la plus probable ?
b) les
bigrammes sur les suites de chunks. Quand on a un chunk de tel type, quelle
est la probabilité pour quil soit suivi par un chunk de tel
type ?
c) les
ambiguïtés lexicales des graphies : étant donnée une chaîne de
caractères, quelle est la probabilité quelle ait telle
analyse ?
d) lanalyse
qui propose le nombre minimal de chunks est favorisée. Ce qui revient à
privilégier les chunks qui couvrent un nombre important de
mots.
En résumé, on peut exprimer quatre
choses importantes :
a)
lalgorithme délagage conditionne grandement la qualité des
analyses.
b) le chunker
est un dispositif hybride mi-symbolique mi-statistique. On peut le décrire par
la maxime suivante : « on essaie de manière symbolique, si cela ne
fonctionne pas, on essaie de manière statistique ».
c) il ny a
pas une phase de « tagging » puis en séquence, une phase de
« chunking », comme dans certains systèmes. Cest le
« chunking » qui pilote le choix des étiquettes et donc réalise le
« tagging ».
d) même si le
sujet de larticle nest pas de présenter en détail le jeu des 188 étiquettes,
le choix de ces étiquettes est crucial pour lobtention dune bonne analyse.
Certaines étiquettes sont affectées à beaucoup de mots, mais dautres ne sont
affectées quà un nombre très restreint de mots. Les étiquettes sont très
précises pour les mots grammaticaux du français. Le rôle du lexique est donc
loin dêtre négligeable car les étiquettes agissent comme des déclencheurs sur
des micro-grammaires (c.f. chapitre sur le
corpus).
5 Mécanisme de construction de
la grammaire
Par convention, nous appelons grammaire, le
triplet formé par :
a) lautomate
de reconnaissance. Cest la représentation de lordre dans lequel chaque nom
de chunk apparaît dans le corpus dapprentissage.
b) les
micro-grammaires. Chacune delle reconnaît les chunks dun certain type. Une
micro-grammaire est composée du nom de chunk quelle reconnaît et de la liste
des suites des étiquettes qui composent le chunk. Une suite détiquettes
représente une analyse possible. Il y a 21 micro-grammaires.
c) les
matrices statistiques destinées à lalgorithme
délagage.
La grammaire nest pas directement écrite
par un humain. Un corpus de phrases a été annoté avec des marques
morpho-syntaxiques et cest ce corpus qui est transformé en grammaire.
Le corpus annoté comporte 18 000 mots. Le corpus a été annoté entièrement à la
main avec beaucoup dattention, puis vérifié par un programme de la manière
suivante :
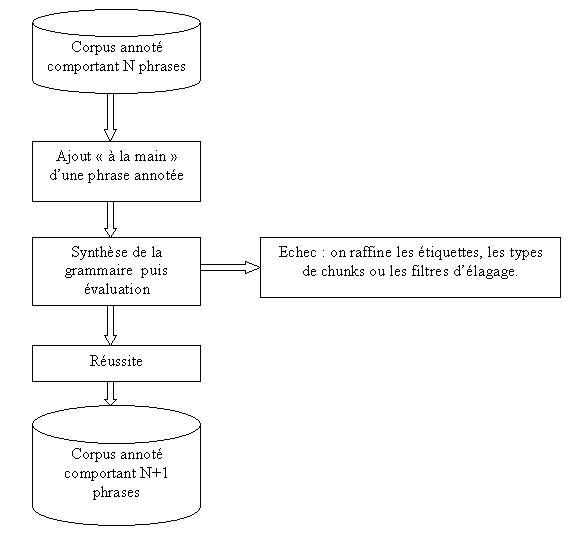
Lautomate est en fait la totalité des
chemins danalyse en conservant lordonnancement des types de chunks.
Lévaluation consiste à appliquer la grammaire apprise sur le corpus
initial : le même résultat doit être obtenu.
En ce qui concerne la méthodologie de
construction, les étiquettes, les types de chunks et les filtres délagage ont
été obtenus par essai-erreur.
6 choix et évolution du corpus
dapprentissage
Le corpus est envisagé comme moyen de
décrire une grammaire.
Lorsque le travail sur TagChunker a
commencé, il nexistait pas de corpus français annoté en syntaxe comme il en
existe en anglais [Marcus 93][Sampson 95].
Nous avons donc annoté nous-même un corpus. Même si un corpus avait existé, il
aurait sans doute fallu raffiner lannotation du fait de la finesse de notre jeu
détiquettes.
Le corpus dapprentissage est composé de
trois parties :
a) corpus noyau.
Ce sont des phrases inventées simples qui
sont organisées par phénomène syntaxique. Il y a par exemple un fichier des
groupes nominaux, un fichier des groupes adjectivaux, un fichier pour les dates
etc. Ce corpus permet ainsi, par le biais des exemples, de poser une grammaire
élémentaire du français en combinant des micro-grammaires.
b) corpus par échantillons pris au
hasard.
Ce sont des phrases prises au hasard dans
des textes législatifs, des romans, des journaux et des dépêches de presse. Les
structures syntaxiques concernées sont relativement différentes les unes des
autres. La longueur des phrases est très variable. Ce corpus a été ajouté dans
une deuxième phase, donc après avoir établi une grammaire noyau, afin dinjecter
des phrases complexes dans lapprentissage. Lobjectif est double, il sagit
dune part de compléter les chunks « oubliés » dans la grammaire
noyau, mais surtout de déclarer les ordonnancements possibles des phrases
complexes.
c) corpus des échecs.
Une fois, les deux corpus précédents
stabilisés, un troisième corpus a été ajouté pour traiter les cas non couverts
par les corpus précédents. Ce corpus est constitué de dépêches de presse. En
effet, lannotation est très fastidieuse et continuer à annoter des phrases
prises au hasard aurait été contre-productif. Il est en effet plus intéressant
de traiter un cas non couvert plutôt que dannoter une phrase dont la structure
syntaxique est déjà décrite.
Voici le dénombrement du
corpus :
|
|
Nb de phrases |
pourcentage |
|
Corpus noyau |
565 |
52 % |
|
Corpus des
échantillons |
434 |
40 % |
|
Corpus des échecs |
86 |
8 % |
|
total |
1085 |
100
% |
Actuellement, le seul corpus en augmentation
est le corpus des échecs et cette opération vient de commencer. La démarche est
itérative et repose sur une évaluation continuelle via le
chunker.
Les opérations peuvent être schématisées par
le diagramme suivant :
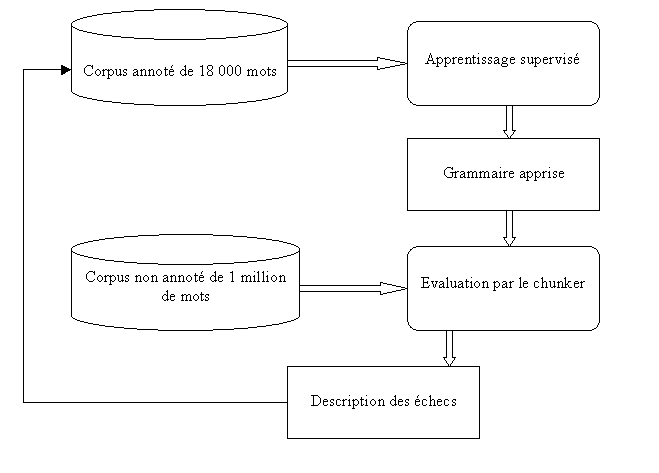
Il nest pas très facile de choisir parmi
les échecs, la phrase qui apportera linformation la plus intéressante pour le
système, car pour chaque échec, nous ne connaissons pas (automatiquement) la
bonne analyse. En nous fondant sur le fait que plus la phrase est longue, plus
elle est pénible à annoter, il vaut mieux sélectionner les phrases les plus
courtes pour les annoter en priorité : cest ce que nous faisons. Un autre
critère nous a conforté dans notre choix est quen sintéressant aux phrases
courtes qui posaient problème, nous avons trouvé immédiatement les erreurs
produites par la segmentation. Il y en avait une cinquantaine au départ.
7 Evaluation
Le rappel est
défini comme le nombre danalyses correctes produites sur le nombre
danalyses demandées. De manière plus intuitive, le rappel mesure le silence (en
fait son inverse) dont fait preuve le système quand il ne trouve aucune
analyse.
La précision est définie comme le nombre
danalyses correctes produites sur le nombre danalyses produites. La précision
mesure donc le bruit produit par le système.
Autrement dit, si lon
définit :
CP = nombre danalyses correctes
produites
NP = nombre danalyses non
produites
IP = nombre danalyses incorrectes
produites
Rappel = CP/(CP+NP)
et
Précision =
CP/(CP+IP)
Et, pour disposer dune valeur globale (mais
grossière) on calcule la F-Mesure comme étant :
FM = (2*Rappel*Précision) /
(Rappel+Précision)
Nous avons trois types
dévaluation :
a) lévaluation lors de lajout dune
phrase. On sassure que le système sauto-applique avec succès à son propre
corpus dapprentissage.
b) lévaluation sur le grand corpus non
annoté. Le mesure fournie permet de connaître le rappel, par le biais du taux
déchecs, mais nous ne pouvons pas connaître la précision.
c) lévaluation sur un corpus annoté de
tests. Lannotation est identique à lannotation du corpus dapprentissage. Les
phrases ont été choisies au hasard dans un roman et des dépêches dagence. Sa
taille est denviron 10% du corpus dapprentissage. Cette évaluation permet de
mesurer à la fois le rappel et la précision. Cest dailleurs la seule mesure de
précision que nous ayons.
|
|
Nb de mots |
Rappel |
Précision |
F-Mesure |
|
Corpus
dapprentissage |
17,0 K |
100 % |
100 % |
100 % |
|
Corpus
non annoté |
1025,0 K |
80 % |
non calculée |
non calculée |
|
Corpus
de test |
1,5 K |
83 % |
66 % |
74 % |
On observe que la précision nest pas très
bonne, mais la tâche est difficile. Les phrases en question ne sont pas des
phrases jouets. Ce sont des phrase réelles. Certaines de ces phrases sont complexes et le test est relativement
sévère. Une phrase est considérée comme bonne si elle remplie les trois
conditions suivantes :
a) la
désambiguïsation lexicale (i.e. tagging) doit être correcte.
b) les
frontières de mots doivent être correctement déterminées.
c) les noms
des chunks doivent être correctement fixés.
Sil sagissait de mesurer la seule
désambiguïsation lexicale comme dans la campagne dévaluation Grace [Paroubek
00], les résultats seraient évidemment meilleurs. Faute de temps, nous ne les
avons pas calculés.
8 Utilité des
évaluations
Lobjectif nest pas de comparer notre
système à un autre analyseur comme dans la campagne Evalda-Easy.
Nous réalisons des évaluations de manière
continuelle afin de faire émerger les situations
suivantes :
a) détecter
les circonstances de régression. Il ne faut pas que lajout dannotations ou
des modifications dans les filtres délagage dégradent la qualité du
résultat.
b) permettre
de décider quelles sont les actions à privilégier. En général, il faut choisir
entre le rappel, la précision et la vitesse de
traitement.
Notre
démarche ne procède pas en deux étapes : i) lélaboration du système, ii)
son évaluation. Au contraire, lévaluation est quotidienne. Elle vérifie et
dirige lélaboration.
9 Amélioration de
lévaluation
Lévaluation décrite ici est le mécanisme
actuellement mis en oeuvre. Lobservation immédiate que lon peut tirer du
tableau est que lon ne mesure pas très bien la précision du fait de la taille
réduite du corpus de test.
En revanche, la mesure de rappel est beaucoup plus fiable. Si dans quelques
mois, dans le cadre de la campagne dévaluation Evalda-Easy, il est possible
davoir accès à un corpus annoté de bonne qualité, nous pourrons alors mesurer
plus sereinement la précision.
10 lavenir
A court terme,
le corpus annoté va être augmenté des groupes non encore reconnus. Il sagira
daméliorer le rappel, et ainsi élargir la couverture.
Au lieu de se
focaliser sur les échecs, il semble possible dévaluer groupe par groupe pour
détecter sur quel type de phénomène syntaxique, le système doit être amélioré.
Le problème est que le temps est compté : plus on passe de temps à raffiner
lévaluation, moins il en reste pour développer.
A long terme,
il nest pas très clair sil est plus intéressant daméliorer le rappel et la
précision en conservant le mécanisme actuel, ou bien sil faut se préoccuper de
produire une analyse un peu plus complète comme un regroupement des chunks en
clauses. Cest ce que font les systèmes IPS [Wehrli 92], IFSP [Aït-Mokthar 97],
XIP ou lanalyseur du GREYC [Giguet 97].
Suivant Abney, la sélection lexicale semble la
technique la plus prometteuse : « The relationships between chunks are
mediated more by lexical selection than by rigid templates » [Abney 91].
Il sagirait alors de combiner des structures actancielles [Tesnière 59]
lexicalisées avec une grammaire des subordonnées et des
circonstants.
Parce que, même si lusage externe du
système est de « tagger » des textes ou bien de réaliser un
« chunking », il nest pas interdit au système de faire appel, de
manière interne à des connaissances qui dépassent ces niveaux danalyse. On peut
imaginer un système danalyse syntaxique et sémantique robuste dont le seul
résultat exploité est une désambiguïsation lexicale, seulement un tel système
aurait une fenêtre danalyse et donc une qualité bien supérieure à un tagger
fondé sur des trigrammes lexicaux par exemple. Mais il faut éviter, que sous
prétexte de réaliser une analyse en profondeur, le système devienne fragile.
Lanalyseur idéal est un système qui analyse en profondeur quand cest possible,
et dans le cas contraire, se comporte comme un chunker.
11 Conclusion
Lévaluation
est utile car nous constatons que les actions menées jusquà présent ont
amélioré le système. Et nous posons lhypothèse que le système peut encore être
amélioré grâce à ce genre daction. On sarrête quand il ny a plus de
progression : on est alors dans un optimum local ou global.
Mais, pour un
changement radical (lajout dun niveau danalyse, par exemple) largument ne
tient plus : la chose mesurable na pas de passé puisquelle nexiste pas
du tout.
En
conclusion, pour une décision à long terme, au contraire dune amélioration
locale, lévaluation nest pas dun grand secours.
Bibliographie
[Abeillé 00]
Abeillé, A., Blache, P., Grammaires et analyseurs syntaxiques. In Pierrel, J.M.,
(eds) Ingénierie des langues. Hermès.
[Abeillé 01]
Abeillé, A., Clément, L., Kinyon, A., Toussenel, F. Un corpus français
arboré : quelques interrogations. In Actes de la conférence sur le
traitement automatique de la langue naturelle, Tours.
[Abney 91] Abney,
S. Parsing by chunks. In
Berwick, R., Abney, S., Tenny, C. (eds) Principle-based parsing.
Kluwer.
[Abney 96] Abney, S. Part-of-speech tagging and
partial parsing. In Church, K., Young, Y., Bloothooft, G., (eds) Corpus-based
methods in Language and speech. Kluwer.
[Aït-Mokthar 97] Aït-Mokthar, S. Chanod, J.
Incremental finite-state parsing. In Proceeding of ANLP-97,
Washington.
[Francopoulo 86] Francopoulo, G. Machine
learning as a tool for building a deterministic parser. In Proceeding of
GWAI-86.
Springer-Verlag.
[Gala 01] Gala Pavia, N., A two-tier
corpus-based approach to robust syntactic annotation of unrestricted corpora.
In Daille, B., Romary, L. (eds) Linguistique de corpus, Traitement
automatique des langues Vol 42 . Hermès.
[Giguet 97] Giguet, E., Vergne, J. From
part-of-speech tagging to memory-based deep syntactic analysis. In Proceeding
of IWPT97, Boston, Massachussets.
[Marcus 93] Marcus, M.P., Santorini, B.,
Marcinkiewicz, M.A. Building a large annotated corpus of english : the Penn
treebank. Computational Linguistics, 19.
[Monceaux 02]
Monceaux, L. Adaptation du niveau danalyse des interventions dans un
dialogue : application à un système de question-réponse. Thèse Paris-11
effectuée au LIMSI.
[Paroubek 00] Paroubek, P., Rajman, M.
Etiquetage morpho-syntaxique. In Pierrel, J.M. (eds) Ingénierie des
langues. Hermès.
[Sampson 95] Sampson, G. English for the
computer : The susanne corpus and analytic scheme. Clarendon Press
Oxford.
[Tesnière 59]
Tesnière, L. Eléments de syntaxe structurale. Kiencksieck.
[Vergne 00] Vergne, J. Trends in robust
parsing. In Tutorial-Coling 2000.
[Wehrli 92] Wehrli, E. The IPS system. In
Proceeding of Coling 1992.